Azure Cloud Services
5.9.22
back

Azure Cloud Services
Welcome to the Azure Data Lake Storage course.
Hope you have a basic understanding of Azure Cloud Services. If not, you must go through the Azure Data Factory and Azure Storage courses before proceeding.
This course introduces you to the fundamental concepts of data lake store and analytics, creating data lake store instances, ingesting data, applying analytics and securing data.
Azure Data Lake Store
Azure data lake store is a highly scalable, distributed,parallel file system that is designed to work with various analytic frameworks, and has the capability of storing varied data from several sources.
Azure Data Lake Store
Microsoft describes Azure Data Lake Store (ADLS) as hyperscale repository for big data analytics workloads that stores data in itsnative format. ADLS is a Hadoop File System compatible with Hadoop Distributed File System (HDFS) that works with the Hadoop ecosystem.
ADLS:
Provides unlimited data storage in different forms.
Is built for running large scale analytic workloads optimally.
Allows storing of relational and non-relational data, and the data schema need not be defined before data is loaded.
The ADLS architecture constitutes three components:
Analytics Service
HDInsight
Diversified Storage
Azure Data Lake - Architecture Components

Analytics Service- to build various data analytic job services, and execute them parallelly.
HDInsight- for managing clusters after ingesting large volumes of data clusters, by extending various open sources such as Hadoop, Spark, Pig, Hive, and so on.
Diversified Storage- to store diversified data such as structured, unstructured, and semi-structured data from diverse data sources.
Azure Data Lake Storage Working

The image above illustrates the ingestion of raw data, the preparation and modeling of data, and the processing of data analytics jobs.
Azure Data Lake Storage Gen 1

Data Lake Storage Gen 1 is an Apache Hadoop file system compatible with HDFS that works with the Hadoop ecosystem. Existing HD Insight applications or services that use the Web HDFS API can easily integrate with Data Lake Storage Gen 1.
The working of a Gen 1 data lake store is illustrated in the above image.
Key Features of Data Lake Store Gen 1
Built for Hadoop: Data stored in ADLS Gen 1 can be easily analyzed by using Hadoop analytic frameworks such as Pig, Hive, and MapReduce. Azure HDInsight clusters can be provisioned and configured to directly access the data stored in ADLS Gen 1.
Unlimited storage: ADLS Gen 1 does not impose any limit on file sizes, or the amount of data to be stored in a data lake. Files can rang from kilobyte to petabytes in size, making it a preferred choice to store any amount of data.
Performance-tuned for big data analytics: A data lakes reads parts of a file over multiple individual storage servers. Therefore, when performing data analytics, it improves read throughput when reading files in parallel.
Key Features of Data Lake Store Gen 1
Enterprise-ready, Highly-available, and Secure: Data assets are stored durably by making extra copies to guard against any unexpected failures. Enterprises can use ADLS Gen 1 in their solutions as an important part of their existing data platform.
All Data: ADLS Gen 1 can store any type of data in its native format without requiring prior transformations, and it does not perform any special handling of data based on the type of data.
Azure Data Lake Store Gen 2
ADLS Gen 2 is built on top of Azure blob storage, dedicated to big data analytics, which is the result of converging both the storage service (blob storage and ADLS Gen 1) capabilities. ADLS Gen 2 is specifically designed for enterprise big data analytics that enables managing massive amounts of data. A fundamental component of ADLS Gen 2 is that it uses hierarchical namespace addition to blob storage, and organizes objects/files into a hierarchy of directories for efficient data access.
ADLS Gen 2 addresses all the drawbacks in areas such as performance, management, security, and cost effectiveness which were compromised in the past in cloud-based analytics.
Key Features of ADLS Gen 2’
Comparing Data Lake Store and Blob Storage
Hadoop-compatible access: The new Azure Blob File System(ABFS) driver is enabled within all Apache Hadoop environments, including AzureDatabricks,
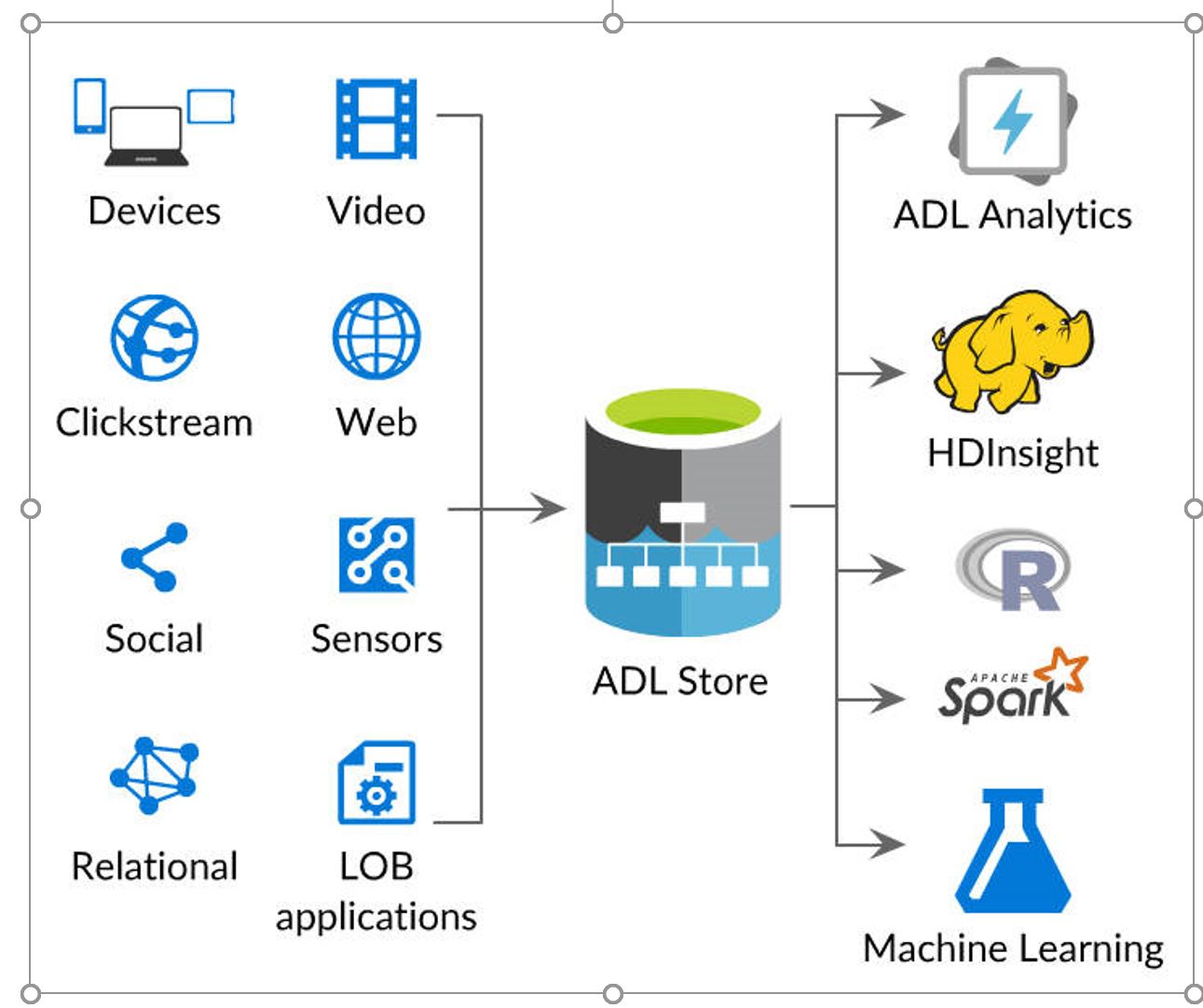
Streamed Data Management

The above image illustrates the data sources for ADLS, andhow data is streamed into usage.
Azure HDInsight, and SQL Data Warehouse, to access datastored in ADLS Gen2.
A superset of POSIX permissions: The security model for ADLSGen2 supports ACL and POSIX permissions, along with extra granularity specificto ADLS Gen2.
Cost effective: ADLS Gen2 offers low-cost storage capacityand transactions as data transitions through its entire life cycle.
Streamed Data Management
The image in the previous card illustrates how streamed datais managed by using ADLS in three different layers:
Data generation
Storage
Data processing
Data is generated from various sources such as cloud, localmachines, or logs.
Data is stored in a data lake store which uses differentanalytic jobs such as Hadoop, Spark, or Pig to analyze the data.
After data analysis, the data is processed for use.
=
Schema
This section describes the following:
Pricing data lake store
Provisioning data lake store
Deploying data lake store by using various management tools
Ingesting data into the store
Moving data from adl to different sources
Moving data by using Adlcopy
Note: The Azure portal interface changes continuously withupdates. The videos may differ from the actual interface, but the corefunctionality remains the same.
https://www.youtube.com/watch?v=6v6KVlm4zYA
Creating ADLS Gen 1 by using CLI
Azure CLI is one of the options with which you can manage datalake store.
The following command is a sample CLI command to create a data lake storage Gen 1 account:
az dls fs create --account $account_name --path /mynewfolder--folder
The above CLI command creates a data lake store Gen 1account, and a folder named mynewfolder at the root of the data lake storageGen 1 account.
Note: The --folder parameter ensures that the command creates a folder, if not, it creates an empty file named mynewfolder, at the root as default.
Data Lake Store Gen 2 Creation
To create a data lake Storage V2 account:
Login to the Azure portal, and navigate to the storageaccount resource.
Add storage account and provide the resource groupname, storage account name, location, and performance (standard or premium).
Select the account type as Storage V2, which is a Gen 2type of account.
Select the replication based on your requirement,such as LRS, GRS, or RA-GRS, and proceed to next for advancedoptions.
Enable the hierarchical namespace to organize the objects orfiles for efficient data access.
Proceed to next, validate, and create the storageaccount.
Azure Data Lake Storage Gen 2

Getting Data into Data Lake Store
You can get your data into your data lake store account in two ways,
Through direct upload method or Adl copy
Set up a pipeline by using data factory, and process data from various sources.
Note: Setting up a pipeline by using data factory, and copying data into a data lake store from various sources is explained in the Azure Data Factory course.
The other upload or copying methods are explained in the following cards.
Copying Data into ADLS
After successful creation of the data lake storage account(Gen 1 or Gen 2), navigate to the resource page.
To ingest data into the storage account through offline copy(directly uploading data from portal),
Navigate to the storage account instance page.
Select Data explorer. The storage account files explorer page appears.
Choose the upload option from the menu, and from the source, select the files you want to be stored in your account.
Upload the files by selecting Add the select files.
]Data Upload by using Azure CLI
The CLI command to upload data into the data lake storage account is:
az dls fs upload --account $account_name --source-path"/path" --destination-path "/path"
Provide the storage account name, source path, and destination path in the above CLI command.
Example:
az dls fs upload --account mydatalakestoragegen1--source-path "C:\SampleData\AmbulanceData\vehicle1_09142014.csv"--destination-path "/mynewfolder/vehicle1_09142014.csv"
AdlCopy Tool
ADLS Gen 1 provides a command line tool AdlCopy to copy data from the following sources:
From azure storage blobs to data lake storage Gen 1 account.
Note: You cannot use AdlCopy to copy data from ADLS Gen 1 toblob.
Between two data lake storage Gen 1 accounts.
You should have AdlCopy tool installed in your machine. Toinstall, use link.
AdlCopy syntax:
AdlCopy /Source <Blob or Data Lake Storage Gen1source> /Dest <Data Lake Storage Gen1 destination> /SourceKey <Keyfor Blob account> /Account <Data Lake Analytics account> /Units<Number of Analytics units> /Pattern
Moving Data by using AdlCopy
Let's assume that data is being copied between two data lakestores named Adls1 and Adls2, where the source is Adls1 and destination isAdls2.
The following example command will perform the copyactivity:
AdlCopy /Sourceadl://adls1.azuredatalakestore.net/testfolder/sampledata.csv /destadl://adls2.azuredatalakestore.net/testfolder
Specify the source, destination instances URL, and the datafile that needs to be copied.
Note: To get the instances URL, navigate to the instancedashboard.
Azure Data Lake Analytics
Azure data lake analytics is an analytics job service thatwrites queries, extracts valuable insights from any scale of data, andsimplifies big data.
It can handle jobs of any scale in a cost-effective manner,where you pay for a job only when it is running.
Data Lake Analytics works with ADLS for high performance,throughput, and parallelization. It works with Azure Storage blobs, Azure SQLDatabase, and Azure Warehouse.
Provisioning Azure Data Lake Analytics
The following video explains how to create a data lakeanalytics instance, along with a data lake store in the Azure portal:
If you have trouble playing this video, please click here for help.
https://www.youtube.com/watch?v=Bdf50VK7M3Y
Manage Data Sources in Data Lake Analytics
Data Lake Analytics supports two data sources:
Data lake store
Azure storage
Data explorer is used to browse the above data sources,and to perform basic file management operations.
To add any of the above data sources,
Login to the Azure portal, and navigate to the Data LakeAnalytics page.
Click data sources, and then click add datasources.
To add a Data Lake Store account, you need the account nameand access to the account, to query it.
To add Azure Blob storage, you need the storage account andthe account key.
Setting Up Firewall Rule
You can enable access to trusted clients only by specifyingan IP address or defining a range of IP addresses, by setting up the firewallrules to cut off access to your data lake analytics at network level.
To setup a firewall rule,
Login to the Azure portal and navigate to your data lakeanalytics account.
On the left menu choose firewall.
Provide the values for the fields by specifying the IPaddresses.
Click OK.
U-SQL Overview
Data lake analytics service runs jobs that query the data togenerate an output for analysis, where these jobs consist of scripts written ina language called U-SQL.
U-SQL is a query language that extends the familiar, simple,declarative nature of SQL; combined with the expressive power of C#, and usesthe same distributed runtime that powers Microsoft's internal exabyte-scaledata lake.
U-SQL Sample Job
The following video explains how to run a job by extracting data from a log file writing a sample U-SQL script for analysis:
https://www.youtube.com/watch?v=XyJnokWY_Ds
Built-in Extractors in U-SQL
Extractors are used to extract data from common types of data sources. U-SQL includes the following built-in extractors:
Extractors.Text - an extractor for generic text file data sources.
Extractors.Csv - a special version of theExtractors.Text extractor specifically for comma-delimited data.
Extractors.Tsv - a special version of theExtractors.Text extractor specifically for tab-delimited data.
Extractor Parameters
The built-in extractors support several parameters you canuse to control how data is read. The following are some of the commonly used parameters:
delimiter- It is a char type parameter that specifies the column separator character whose default column separator value is comma (',').It is only used in Extractors.Text().
rowDelimiter- It is a string type parameter whose max length is 1, which specifies the row separator in a file whose default values are"\r\n" (carriage return, line feed).
skipFirstNRows- It is an Int type parameter whose default value is 0, which specifies the number of rows to skip in a file.
silent- It is a Boolean type parameter whose default value is false, which specifies that the extractor ignore and skip rows that have a different number of columns than the requested number.
Built-in Outputters in U-SQL
U-SQL provides a built-in outputter classcalled Outputters. It provides the following built-in outputters totransform a rowset into a file or set of files*:Outputters.Text()- Providesoutputting a rowset into a variety of delimited text formats.
Outputters.Csv()- Provides outputting a rowset into acomma-separated value (CSV) file of different encodings.
Outputters.Tsv()- Provides outputting a rowset into atab-separated value (TSV) file of different encodings.
Aggregating Data With U-SQL: Demo
https://www.youtube.com/watch?v=Fe7M8dG7JQ4
U-SQL Catalog Overview
Azure data lake analytics allows you to create a catalog ofU-SQL objects that are stored in databases within the data lake store.
The following are some of the objects you can create in anydatabase:
Table: represents a data set of data that you want tocreate, such as creating a table with certain data.
Views: encapsulates queries that abstract tables in yourdatabase, such as writing a view that consists of select statements whichretrieve data from the mentioned tables.
Table valued function: writes custom logic to retrieve thedesired data set for queries.
Procedures: encapsulates the code that performs certaintasks regularly, such as writing a code to insert data into tables or otherregular operations which are executed repeatedly.
Creating a View: Demo
https://www.youtube.com/watch?v=V_a9RgQzZBc
External Tables
Along with managed tables, U-SQL catalogs can also includeexternal tables which reference tables in azure instances such as SQL datawarehouse, SQL database or SQL Server in Azure virtual machines.
This is useful when you have to use U-SQL to process datathat is stored in an existing database in Azure.
To create an external table, use the CREATE DATA SOURCEstatement to create a reference to an external database, and then use the CREATEEXTERNAL TABLE statement to create a reference to a table in that data source.
Table Value Function: Demo
https://www.youtube.com/watch?v=ChGjZ-2ApWM
Procedures: Demo
https://www.youtube.com/watch?v=mqztjuaGdGw







